Cool stuff and UX resources
Death. Taxes. And "the how many users?" debate.
There are a few things that seem inevitable. Death. Taxes. The "Are-Five-Users-Enough?" panel discussion that occurs at every usability conference.
Every conference.
Every year.
These panels are legend. People get excited. Speakers get hyperbolic. Listeners get frustrated.
Repeat.
Listeners get frustrated because the debate rages with the same opinions and no new and compelling data. The answer to the "how-many-users" question is important. However entertaining, the fact that there is no resolution frustrates practitioners who need to know how to justify the choice to test five (6? 10? 90? 150?) users to their management. Understanding the "right" answer (and why it is right) is particularly important for individuals institutionalizing their usability practice. They need to make critical decisions on how to prioritize activities with limited staff time and within a limited budget and a short window to build credibility. So, really... This year they will tell us, right? How many users?

Is so...
For years we have heard that, using the law of diminishing returns, five users will uncover approximately 80% of the usability problems in a product (Virzi, 1992).
In support of this claim, Nielsen (Landauer and Nielsen, 1993; Nielsen, 1993) present a meta-analysis of 13 studies in which they calculate confidence intervals to derive the now famous formula:
Problems found = N(1-(1-L)n)
N = number of known problems
L = the probability of any given user finding any given problem
n = # of participants
Since this function ceilings rapidly at five participants, practitioners typically interpret the formula as advising that five is enough.
Is not...
There are two broad approaches to arguing against the five-user guideline. One approach is to deconstruct the claim on statistical methods. Researchers who take this approach argue that inappropriate calculations were used or that the underlying assumptions are faulty or not met (Grosvenor, 1999; Woolrych and Cockton, 2001).
Others take a more empirical approach. Spool and Schroeder (2001) report that testing the first five revealed only 35% of problems identified by the larger test set. Perfetti and Landesman (2002) show that participants 6-18 (of 18) each identified five or more problems that were not uncovered within the first five user tests.
Do you read the fine print?
In fairness, both Virzi and Nielsen place qualifications on the five-user guideline. Nielsen carefully describes the confidence part of confidence intervals. Virzi warns that "[s]ubjects should be run until the number of new problems uncovered drops to an acceptable level." (p.467).
This leaves unsuspecting readers either to wade through the philosophy of confidence intervals or test until they've tested to an (unspecified but) "acceptable" level. It's no wonder that practitioners blink at the caveats and remember number five.
But is that the right thing to do?
A new way to decide
Faulkner (2003) buttresses the old empirical evaluation with a statistical sampling approach to arrive at a novel new way to determine if five is really enough. She evaluated the five-user guideline in a two phase experiment.
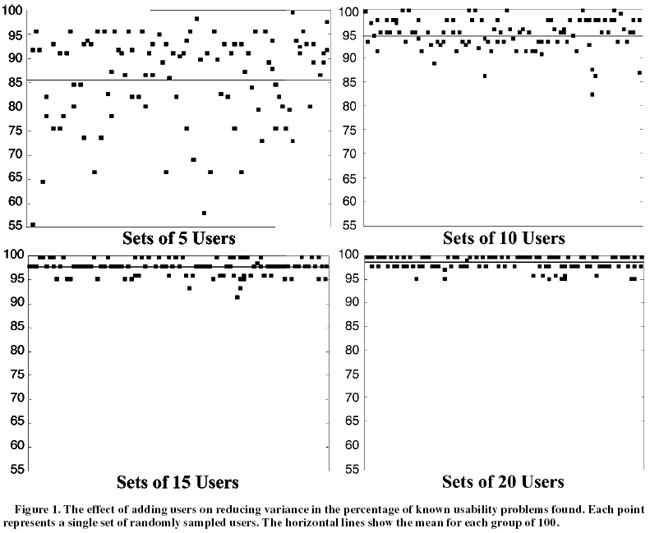
First, she evaluated the usability of a Web-based time sheet application by observing deviations from the optimal path over 60 participants. Then, she used a sampling algorithm to randomly draw smaller sets of individual users' results from the full dataset for independent analysis. Set sizes corresponded to the number of users 'tested' in that simulation. In the course of her experiment she ran 100 simulations each with user group sizes 5, 10, 20, 30, 40, 50 and 60 users.
She found that, on average, Nielsen's prediction is right. Over 100 simulated tests, testing five users revealed an average of 85% of the usability problems identified with the larger group.
Averages are good, but for day-to-day practitioners, the range of problems identified is a more critical figure. The range was not so promising. Over the 100 simulated tests, the percentage of usability problems found when testing five participants ranged from nearly 100% down to only 55%. As any good freshman statistics student could predict, there is a large variation in outcomes between trials with small samples. Extrapolating from Faulkner's findings, usability test designers relying on any single set of five users run the risk that nearly half the problems could be missed.
Increasing the number of participants, however, improves the reliability of the findings quickly. Drawing 10 participants instead of five, the simulation uncovered 95% of the problems on average with a lower bound of 82% of problems identified over 100 simulations. With 15 participants, 97% of the identified problems were uncovered on average, with a lower bound of 90% found.
So? How many then?
So what's the answer? As always in usability, the answer is "It depends." The key to effective usability testing is recruiting a truly representative sample of the target population. Often the test population will need to represent more than one user group.
That aside, Faulkner's work strongly indicates that a single usability test with five participants is not enough.
References
Faulkner, L. (2003). Beyond the five-user assumption: Benefits of increased sample sizes in usability testing. Behavior Research Methods, Instruments and Computers, 35(3), 379-383.
Grosvenor, L. (1999). Software usability: Challenging the myths and assumptions in an emerging field. Unpublished master¹s thesis, University of Texas, Austin.
Landauer, T. K., & Nielsen, J. (1993). A mathematical model of the finding of usability problems. Interchi ¹93, ACM ComputerHuman Interface Special Interest Group.
Nielsen, J. (1993). Usability engineering. Boston: AP Professional.
Perfetti, C., & Landesman, L. (2002). Eight is not enough. Retrieved April 14, 2003.
Spool, J., & Schroeder, W. (2001). Testing web sites: Five users is nowhere near enough. In CHI 2001 Extended Abstracts (pp. 285- 286). New York: ACM Press.
Virzi, R. A. (1992). Refining the test phase of usability evaluation: How many subjects is enough? Human Factors, 34, 457-468.
Woolrych, A., & Cockton, G. (2001). Why and when five test users aren't enough. In J. Vanderdonckt, A. Blandford, & A. Derycke (Eds.), Proceedings of IHM-HCI 2001 Conference: Vol. 2 (pp. 105- 108). Toulouse, France: Cépadèus.
Message from the CEO, Dr. Eric Schaffer — The Pragmatic Ergonomist

So for a routine usability test run 12 people for each segment. For an important one where the stakes are high run 30. If resources are really tight, you can drop to five-six per segment, but this is bad.
Remember I said "FOR EACH SEGMENT." If you are designing a time reporting system for health care workers, government employees, lawyers, and forestry workers, you are making a big mistake if you test just three in each group. That would be 12 people tested, but the groups are quite diverse and you need more people from each segment to be confident.
Leave a comment here
Reader comments
Martha Roden
Usability Engineer
CoCreate Software Inc.
Regarding the "Is 5 Enough?" debate in your newsletter.
If you are the only interaction designer and usability professional in a company of 400 people, AND no one really thinks usability tests are important or wants to free up additional resources to conduct the tests... then believe me ... 5 is definitely better than none!
Five people still find more usability problems than zero people.
James R. (Jim) Lewis, Ph.D., CHFP
Senior Human Factors Engineer
IBM Pervasive Computing Division
As always, I enjoyed the newsletter. I guess I can understand the frustration with the recurring question of sample sizes for usability studies, but it can be an important issue, and the various explorations of it have enhanced our understanding of some of our practices (or at least led to some interesting discussions).
I've ordered the Faulkner paper, and am looking forward to reading it. It sounds similar in method and results to a paper that I published in 2001:
Lewis, J. R. (2001). Evaluation of procedures for adjusting problem-discovery rates estimated from small samples. Journal of Human-Computer Interaction, 13, 445-479.
I was a little surprised that you didn't mention the paper that I published in Human Factors in 1994:
Lewis, J. R. (1994a). Sample sizes for usability studies: Additional considerations. Human Factors, 36, 368-378.
More...Subscribe
Sign up to get our Newsletter delivered straight to your inbox