- About us
- Contact us: +1.641.472.4480, hfi@humanfactors.com
Cool stuff and UX resources

When Discount Usability Misleads Management – A Solution
Summary
Usability folks often interact with marketing folks about progress on Web site design. Do they speak the same language? That is the question. If you tell someone that 80% of your test subjects "succeeded," how might you be misleading them? Know how to qualify your discount usability test results with a "margin of error."

Episode #287 of Usability Crossroads: "Telling It Like It Is"
Narrative processing does much more than influence decision making and memory – it provides an "emotional" interpretation of our experience. It helps us develop our attitudes, preferences, and even our self-concept (Markus & Kunda, 1986). The stories we create and use to make decisions provide meaning and are, in that sense, the full "user experience."
Scene 3: DAY, INTERIOR, USABILITY OFFICE
You (to your buddy who did the test): I just told marketing we found some more problems we can fix on the shopping cart tasks. Solving those two or three problems should get us another bump up in revenue.
Your buddy: Yeah, I guess we'll have to wait and see what happens on the Web site. Anyway, it certainly will be better than what we had before the changes.
Reality quiz
Which is right – Scene 2, Scene 3, Both, or Neither
To end the suspense, the answer is "Neither".
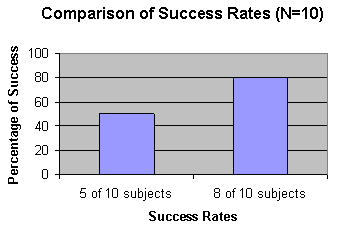
Usability fails to qualify "80%" success rate
Yes, indeed, you "just told marketing we found some more problems". However, you probably mislead your listener because you also said "80%" could do the task – without qualifying what you meant. Qualifying your answer means telling marketing that 80% really only applies to your subjects. Unfortunately, it has many other, inferred meanings – some useful, some downright dangerous.
As you saw in scene 2, marketing interpreted 80% as a real number that was actionable in terms of all the shoppers on your site – not just the subjects in the test. Marketing made the "profit" calculations based on what you said and figured an extra 300 people adds $15,000 to the gross income per day.
But wait a minute, you and your usability buddies all subscribe to the "discount usability" model. Namely, you used just a few subjects – with the intent of finding problems – not statistics about your shoppers.
Therefore, you may have followed Nielsen's model where you hope to find, on average, about 85% of problems with 5 users. Or, you may have followed Faulkner's update (reported here previously by Kath Straub) where you hope to discover at least 82% of problems with 10 users.
Notice the difference between "on average" and "at least"... which would you rather present to you management? "At least" 82% is much more substantive.
But we still haven't gotten to the real issue. The real issue is that when you presented the "80%" success rate to management, you failed to give proper context. You failed to indicate the "margin of error" associated with "80%".
The margin of error shows that it is not still "certain" that you found all the problems – contrary to your buddy's comment "it certainly will be better than what we had before." Consequently, marketing went off and made definitely wrong conclusions.
Marketing fails to question "80%" success rate
Marketing didn't do much better. Marketing failed to ask you how many subjects you had. Marketing apparently didn't know about "margins of error" when applying the test subject results to the population of buyers. These are both technical terms you should know. They each have important practical implications that you simply must have at your command at all times. By the way, many marketing people do know about margins of error. Are you prepared to answer their questions?
Test results like 80% rate of task success merely tell you what happened in the test session. To be honest, in the discount usability model where you use small numbers of subjects, it's a fairly uninteresting number.
Your intent was to find some problems. More subjects let you find more problems. Very simple. But for people interested in making an inference about their population of buyers the 80% is a dangerous number unless it undergoes some transformation. The 80% must be qualified with a margin of error. (See Rea and Parker, 1997, for the whole story on making inferences from samples.)
Voting polls use "margin of error" to qualify success rate
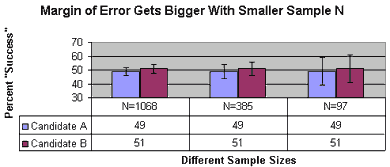
This challenge is no different than qualifying the results of a voting poll. For example, when 49% of prospective voters claim they will vote for Candidate A and 51% claim they will vote for Candidate B, do we have a tie or will Candidate B win?
We all know that such polls come with a "margin of error" typically plus or minus (+/-) 3%. In this case, the candidates tied because the +/- 3% causes the 49% and 51% to overlap.
Note that to get a margin of error as small as +/-3% you need 1068 subjects. Whew. Fewer subjects mean bigger margin of error. 385 subjects get you a margin of error of +/- 5%. 97 subjects get you a margin of error of +/- 10%. You see where we are going with small numbers of subjects.
The discount usability "fix" on margin of error
This challenge is no different than qualifying the results of a voting poll. For example, when 49% of prospective voters claim they will vote for Candidate A and 51% claim they will vote for Candidate B, do we have a tie or will Candidate B win?
We all know that such polls come with a "margin of error" typically plus or minus (+/-) 3%. In this case, the candidates tied because the +/- 3% causes the 49% and 51% to overlap.
Note that to get a margin of error as small as +/-3% you need 1068 subjects. Whew. Fewer subjects mean bigger margin of error. 385 subjects get you a margin of error of +/- 5%. 97 subjects get you a margin of error of +/- 10%. You see where we are going with small numbers of subjects.
Use a 95% confidence level
Let's apply Jeff's calculator to our scenario. The usability team used 10 subjects and 8 passed. So enter those numbers...
What does the 95% Confidence level mean? It means that if you did the same test 100 times, 95 of those tests would yield results that fall within the +/- margin of error. So you would qualify your 80% success rate with a plus and minus "margin of error" wide enough to handle a commonly accepted confidence level.
Conducting the "same test" means the same tasks, similar subjects with similar backgrounds, and similar testing environment, etc.
Are you happy with a 95% level of confidence in your results? For a medical device, you may want a plus/minus range that encompasses 99% or even 99.99% out of 100 tests. However, for practical purposes (and non-lethal interface designs) 95% is commonly accepted.
Presenting your low and high bounds for success rates
OK, now press "Calculate" and see your results.
First, check the "Wald" results. You'd get these results from a typical Web "marketing" calculator. (They work for surveys or tests in which you have more than 150 subjects.) For an 80% success rate, it shows a "low bound" of 55.21% (55%) and a "high bound" of 104.79% (105%). The real results over many tests will fall between these two bounds. Right away, you see one of the limitations of a small sample size. The Wald calculations "blow up" and give a result more than 100%. Meanwhile, the +/- margin of error (given in the right column) shows what you must add and subtract (+/-) (24.79%) to the success rate (80%) to get the low and high boundaries.
Second, check the "Adjusted Wald" results. Use the Adjusted Wald results because they take into account the small number of subjects (under 150). Note the lower bound is now 48.29% (48%) instead of 55%. The upper bound is now 95.62% (96%) instead of 105%.
Everything said, even with this additional accuracy, you see that the range between 48% and 96% is a large departure from saying "80% success rate". Therefore, be reluctant to report success rates with small sample sizes. They mislead the unwary listener.
Jeff's calculator shows two other types of results: "Exact" and "Score" (see illustration above). Use these measures when you have really high or low success rates (above 95% or below 5%). They let you compare with other calculators that use those methods. Most people don't need to worry about these methods.
Choosing which success rate to present
Note that the "P" column ("Probability" of success = success rate) for the Adjusted Wald shows 71.96% (OK, make it 72%). Why does it not show the 80% we started with (8 out of 10)? This is where the method gets its name, the Adjusted Wald method. It's adjusted because you're adjusting the success rate, then computing the margin of error. This new adjusted success rate has a slightly higher chance of being closer to the true population than the unadjusted 80%.
This is a choice you get to make. Jeff explains on his Web page that you could choose to report either of the two success rates (72% or 80%). However, you must stick with the low and high numbers he presents for the Adjusted Wald method.
On the one hand, 72% is useful because you get a "symmetric" margin of error – the upper margin of error matches the lower margin of error. You can just add and subtract the "margin of error" given in the rightmost column of the Results.
On the other hand, 80% is useful because, well, you just don't have to explain it to anybody. That's pretty much the main reason. If using 72% will cause confusion, just use 80%. But make sure you hand-calculate both the minus and the plus margins of error for your charting program. (In Excel, enter data into the "Y-error bars" dialog, discussed below.) The lower margin of error will be big, and the upper margin of error will be small.
Next steps in making your slide show...
Now you know how to rewrite Scene 1 above.
Marketing: Great. What percentage of your test subjects were able to actually get through the shopping cart?
You: We don't collect that kind of data. We do discount usability testing to look for problems, not success rates. What kind of margin of error do you need? With 100 people, we can get about a plus or minus 10%. A tighter margin of error takes more people. Did you know we can do remote unattended usability tests pretty economically?
Now you have a dialog worth repeating.
With discount usability testing of 10 subjects, margins of error like -32% and +16% necessarily accompany an 80% success rate. So you can see the how the success rate of 80% can be misleading when given by itself.
That 80% success rate is really the range of 48% to 96% success rates. This range is called the "confidence interval" and it impacts all conclusions using it. For example, the marketing calculations of increased profit should have used this confidence interval rather than just 80% for the success rate.
If you really, really, really (yup, 3 "reallys") want to compare 80% with a 50% success rate using 10 subjects, the best you can do is to say that 80% success rate allows you to "expect some improvement". Note that a 50% success rate with 10 subjects gives a confidence interval from 24% to 77%.
The overlap of these two confidence intervals prohibits you from saying there is any certainty of improvement. You only have a "chance" of improvement. (In subsequent reports, we'll discuss the advantages of other measures like satisfaction and time on task for comparing pre- and post-redesign data with small numbers of subjects.)
The oval in the illustration below shows the areas of overlap between the two margins of error. The overlap indicates possible test outcomes that could occur in future testing with similar subjects and the same tasks. The overlap shows that the outcomes could have been the same many times out of 100.
Conclusion and future topics in quantitative usability
Discount usability testing pays its way by helping you discover problems before your site or application goes public. It was not really meant to determine a success rate. But, discovering problems is important. As Jakob Nielsen and others have said about discount usability engineering "any data is data" and "anything is better than nothing." We continue to endorse that position.
Meanwhile, many things can be said about "quantitative usability" that help position or clarify the significance of your usability testing even with small sample sizes. For example, how can you characterize the efficiency of small sample sizes in discovering problems?
Some problems have a greater chance of being found by any of your test subjects. Other problems have less chance of being found. In an upcoming newsletter, we'll discuss how you can report the efficiency of your discount usability testing in a manner that makes sense.
James Lewis, the esteemed co-author with Jeff on the paper mentioned here, is one of the leaders striving to characterize small sample test results. We'll discuss some of his and other's findings in future newsletters.
References
Bartlett, J.E., Kotrlik, J.W., Higgins, C.C. (2001). Determining appropriate sample size in survey research. Information Technology, Learning, and Performance Journal, 19 (1), pp. 43-50.
Rea, L.M. and Parker, R.A. (1997) Designing and Conducting Survey Research, 2nd Ed., Jossey-Bass, Inc.
Sauro, J & Lewis, J.R (In Press). Estimating completion rates from small samples using binomial confidence intervals: comparisons and recommendations. Proceedings of the Human Factors and Ergonomics Society Annual Meeting (HFES 2005), Orlando, FL.
Message from the CEO, Dr. Eric Schaffer — The Pragmatic Ergonomist

Our scientific approach is what makes usability professionals different from designers who just guess. But science is more than just running tests. You have to be able to interpret the data. I have seen (to my horror) presentations at usability conferences that reported 6 out to 10 participants preferred a given version. As John points out, that does not mean a THING.
We don't need every usability professional to master experimental design and statistics. But we must ALL be able to understand the meaning of the results we read and create.
Studies with small numbers are designed to find problems and insights. It takes a very different type of study to create numbers that can be generalized to accurate projections.
Leave a comment here
Reader comments
John Imms DST Systems
Terrific article and a real service to call attention to Sauro's work and practical Web site. The HFI newsletters consistently provide insightful, dare I say useful, summaries and perspectives to the practicing professional. And they are free! May they bring you many eager customers. Thanks
Robert Thompson
Option One Mortgage Company
Very good article. It is important to understand when communicating the meaning of our testing results.
Dann Nebbe
Principal Finacial Group
A very thought-provoking article about how to communicate usability results (and set expectations) for tests with low numbers of participants. Having a high-level understanding of statistics, I really appreciate having the tool to use to calculate confidence intervals, too.
Subscribe
Sign up to get our Newsletter delivered straight to your inbox
Privacy policy
Reviewed: 18 Mar 2014
This Privacy Policy governs the manner in which Human Factors International, Inc., an Iowa corporation (“HFI”) collects, uses, maintains and discloses information collected from users (each, a “User”) of its humanfactors.com website and any derivative or affiliated websites on which this Privacy Policy is posted (collectively, the “Website”). HFI reserves the right, at its discretion, to change, modify, add or remove portions of this Privacy Policy at any time by posting such changes to this page. You understand that you have the affirmative obligation to check this Privacy Policy periodically for changes, and you hereby agree to periodically review this Privacy Policy for such changes. The continued use of the Website following the posting of changes to this Privacy Policy constitutes an acceptance of those changes.
Cookies
HFI may use “cookies” or “web beacons” to track how Users use the Website. A cookie is a piece of software that a web server can store on Users’ PCs and use to identify Users should they visit the Website again. Users may adjust their web browser software if they do not wish to accept cookies. To withdraw your consent after accepting a cookie, delete the cookie from your computer.
Privacy
HFI believes that every User should know how it utilizes the information collected from Users. The Website is not directed at children under 13 years of age, and HFI does not knowingly collect personally identifiable information from children under 13 years of age online. Please note that the Website may contain links to other websites. These linked sites may not be operated or controlled by HFI. HFI is not responsible for the privacy practices of these or any other websites, and you access these websites entirely at your own risk. HFI recommends that you review the privacy practices of any other websites that you choose to visit.
HFI is based, and this website is hosted, in the United States of America. If User is from the European Union or other regions of the world with laws governing data collection and use that may differ from U.S. law and User is registering an account on the Website, visiting the Website, purchasing products or services from HFI or the Website, or otherwise using the Website, please note that any personally identifiable information that User provides to HFI will be transferred to the United States. Any such personally identifiable information provided will be processed and stored in the United States by HFI or a service provider acting on its behalf. By providing your personally identifiable information, User hereby specifically and expressly consents to such transfer and processing and the uses and disclosures set forth herein.
In the course of its business, HFI may perform expert reviews, usability testing, and other consulting work where personal privacy is a concern. HFI believes in the importance of protecting personal information, and may use measures to provide this protection, including, but not limited to, using consent forms for participants or “dummy” test data.
The Information HFI Collects
Users browsing the Website without registering an account or affirmatively providing personally identifiable information to HFI do so anonymously. Otherwise, HFI may collect personally identifiable information from Users in a variety of ways. Personally identifiable information may include, without limitation, (i)contact data (such as a User’s name, mailing and e-mail addresses, and phone number); (ii)demographic data (such as a User’s zip code, age and income); (iii) financial information collected to process purchases made from HFI via the Website or otherwise (such as credit card, debit card or other payment information); (iv) other information requested during the account registration process; and (v) other information requested by our service vendors in order to provide their services. If a User communicates with HFI by e-mail or otherwise, posts messages to any forums, completes online forms, surveys or entries or otherwise interacts with or uses the features on the Website, any information provided in such communications may be collected by HFI. HFI may also collect information about how Users use the Website, for example, by tracking the number of unique views received by the pages of the Website, or the domains and IP addresses from which Users originate. While not all of the information that HFI collects from Users is personally identifiable, it may be associated with personally identifiable information that Users provide HFI through the Website or otherwise. HFI may provide ways that the User can opt out of receiving certain information from HFI. If the User opts out of certain services, User information may still be collected for those services to which the User elects to subscribe. For those elected services, this Privacy Policy will apply.
How HFI Uses Information
HFI may use personally identifiable information collected through the Website for the specific purposes for which the information was collected, to process purchases and sales of products or services offered via the Website if any, to contact Users regarding products and services offered by HFI, its parent, subsidiary and other related companies in order to otherwise to enhance Users’ experience with HFI. HFI may also use information collected through the Website for research regarding the effectiveness of the Website and the business planning, marketing, advertising and sales efforts of HFI. HFI does not sell any User information under any circumstances.
Disclosure of Information
HFI may disclose personally identifiable information collected from Users to its parent, subsidiary and other related companies to use the information for the purposes outlined above, as necessary to provide the services offered by HFI and to provide the Website itself, and for the specific purposes for which the information was collected. HFI may disclose personally identifiable information at the request of law enforcement or governmental agencies or in response to subpoenas, court orders or other legal process, to establish, protect or exercise HFI’s legal or other rights or to defend against a legal claim or as otherwise required or allowed by law. HFI may disclose personally identifiable information in order to protect the rights, property or safety of a User or any other person. HFI may disclose personally identifiable information to investigate or prevent a violation by User of any contractual or other relationship with HFI or the perpetration of any illegal or harmful activity. HFI may also disclose aggregate, anonymous data based on information collected from Users to investors and potential partners. Finally, HFI may disclose or transfer personally identifiable information collected from Users in connection with or in contemplation of a sale of its assets or business or a merger, consolidation or other reorganization of its business.
Personal Information as Provided by User
If a User includes such User’s personally identifiable information as part of the User posting to the Website, such information may be made available to any parties using the Website. HFI does not edit or otherwise remove such information from User information before it is posted on the Website. If a User does not wish to have such User’s personally identifiable information made available in this manner, such User must remove any such information before posting. HFI is not liable for any damages caused or incurred due to personally identifiable information made available in the foregoing manners. For example, a User posts on an HFI-administered forum would be considered Personal Information as provided by User and subject to the terms of this section.
Security of Information
Information about Users that is maintained on HFI’s systems or those of its service providers is protected using industry standard security measures. However, no security measures are perfect or impenetrable, and HFI cannot guarantee that the information submitted to, maintained on or transmitted from its systems will be completely secure. HFI is not responsible for the circumvention of any privacy settings or security measures relating to the Website by any Users or third parties.
Correcting, Updating, Accessing or Removing Personal Information
If a User’s personally identifiable information changes, or if a User no longer desires to receive non-account specific information from HFI, HFI will endeavor to provide a way to correct, update and/or remove that User’s previously-provided personal data. This can be done by emailing a request to HFI at hfi@humanfactors.com. Additionally, you may request access to the personally identifiable information as collected by HFI by sending a request to HFI as set forth above. Please note that in certain circumstances, HFI may not be able to completely remove a User’s information from its systems. For example, HFI may retain a User’s personal information for legitimate business purposes, if it may be necessary to prevent fraud or future abuse, for account recovery purposes, if required by law or as retained in HFI’s data backup systems or cached or archived pages. All retained personally identifiable information will continue to be subject to the terms of the Privacy Policy to which the User has previously agreed.
Contacting HFI
If you have any questions or comments about this Privacy Policy, you may contact HFI via any of the following methods:
Human Factors International, Inc.
PO Box 2020
1680 highway 1, STE 3600
Fairfield IA 52556
hfi@humanfactors.com
(800) 242-4480
Terms and Conditions for Public Training Courses
Reviewed: 18 Mar 2014
Cancellation of Course by HFI
HFI reserves the right to cancel any course up to 14 (fourteen) days prior to the first day of the course. Registrants will be promptly notified and will receive a full refund or be transferred to the equivalent class of their choice within a 12-month period. HFI is not responsible for travel expenses or any costs that may be incurred as a result of cancellations.
Cancellation of Course by Participants (All regions except India)
$100 processing fee if cancelling within two weeks of course start date.
Cancellation / Transfer by Participants (India)
4 Pack + Exam registration: Rs. 10,000 per participant processing fee (to be paid by the participant) if cancelling or transferring the course (4 Pack-CUA/CXA) registration before three weeks from the course start date. No refund or carry forward of the course fees if cancelling or transferring the course registration within three weeks before the course start date.
Cancellation / Transfer by Participants (Online Courses)
$100 processing fee if cancelling within two weeks of course start date. No cancellations or refunds less than two weeks prior to the first course start date.
Individual Modules: Rs. 3,000 per participant ‘per module’ processing fee (to be paid by the participant) if cancelling or transferring the course (any Individual HFI course) registration before three weeks from the course start date. No refund or carry forward of the course fees if cancelling or transferring the course registration within three weeks before the course start date.
Exam: Rs. 3,000 per participant processing fee (to be paid by the participant) if cancelling or transferring the pre agreed CUA/CXA exam date before three weeks from the examination date. No refund or carry forward of the exam fees if requesting/cancelling or transferring the CUA/CXA exam within three weeks before the examination date.
No Recording Permitted
There will be no audio or video recording allowed in class. Students who have any disability that might affect their performance in this class are encouraged to speak with the instructor at the beginning of the class.
Course Materials Copyright
The course and training materials and all other handouts provided by HFI during the course are published, copyrighted works proprietary and owned exclusively by HFI. The course participant does not acquire title nor ownership rights in any of these materials. Further the course participant agrees not to reproduce, modify, and/or convert to electronic format (i.e., softcopy) any of the materials received from or provided by HFI. The materials provided in the class are for the sole use of the class participant. HFI does not provide the materials in electronic format to the participants in public or onsite courses.