- About us
- Contact us: +1.641.472.4480, hfi@humanfactors.com
Cool stuff and UX resources
Death. Taxes. And "the how many users?" debate.
There are a few things that seem inevitable. Death. Taxes. The "Are-Five-Users-Enough?" panel discussion that occurs at every usability conference.
Every conference.
Every year.
These panels are legend. People get excited. Speakers get hyperbolic. Listeners get frustrated.
Repeat.
Listeners get frustrated because the debate rages with the same opinions and no new and compelling data. The answer to the "how-many-users" question is important. However entertaining, the fact that there is no resolution frustrates practitioners who need to know how to justify the choice to test five (6? 10? 90? 150?) users to their management. Understanding the "right" answer (and why it is right) is particularly important for individuals institutionalizing their usability practice. They need to make critical decisions on how to prioritize activities with limited staff time and within a limited budget and a short window to build credibility. So, really... This year they will tell us, right? How many users?

Is so...
For years we have heard that, using the law of diminishing returns, five users will uncover approximately 80% of the usability problems in a product (Virzi, 1992).
In support of this claim, Nielsen (Landauer and Nielsen, 1993; Nielsen, 1993) present a meta-analysis of 13 studies in which they calculate confidence intervals to derive the now famous formula:
Problems found = N(1-(1-L)n)
N = number of known problems
L = the probability of any given user finding any given problem
n = # of participants
Since this function ceilings rapidly at five participants, practitioners typically interpret the formula as advising that five is enough.
Is not...
There are two broad approaches to arguing against the five-user guideline. One approach is to deconstruct the claim on statistical methods. Researchers who take this approach argue that inappropriate calculations were used or that the underlying assumptions are faulty or not met (Grosvenor, 1999; Woolrych and Cockton, 2001).
Others take a more empirical approach. Spool and Schroeder (2001) report that testing the first five revealed only 35% of problems identified by the larger test set. Perfetti and Landesman (2002) show that participants 6-18 (of 18) each identified five or more problems that were not uncovered within the first five user tests.
Do you read the fine print?
In fairness, both Virzi and Nielsen place qualifications on the five-user guideline. Nielsen carefully describes the confidence part of confidence intervals. Virzi warns that "[s]ubjects should be run until the number of new problems uncovered drops to an acceptable level." (p.467).
This leaves unsuspecting readers either to wade through the philosophy of confidence intervals or test until they've tested to an (unspecified but) "acceptable" level. It's no wonder that practitioners blink at the caveats and remember number five.
But is that the right thing to do?
A new way to decide
Faulkner (2003) buttresses the old empirical evaluation with a statistical sampling approach to arrive at a novel new way to determine if five is really enough. She evaluated the five-user guideline in a two phase experiment.
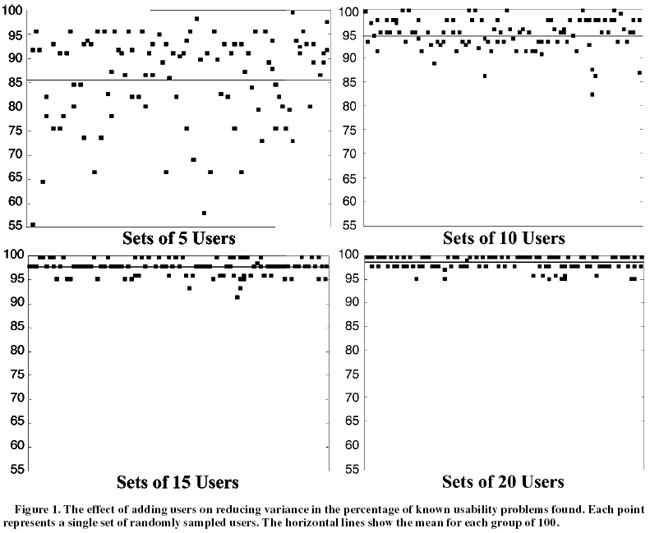
First, she evaluated the usability of a Web-based time sheet application by observing deviations from the optimal path over 60 participants. Then, she used a sampling algorithm to randomly draw smaller sets of individual users' results from the full dataset for independent analysis. Set sizes corresponded to the number of users 'tested' in that simulation. In the course of her experiment she ran 100 simulations each with user group sizes 5, 10, 20, 30, 40, 50 and 60 users.
She found that, on average, Nielsen's prediction is right. Over 100 simulated tests, testing five users revealed an average of 85% of the usability problems identified with the larger group.
Averages are good, but for day-to-day practitioners, the range of problems identified is a more critical figure. The range was not so promising. Over the 100 simulated tests, the percentage of usability problems found when testing five participants ranged from nearly 100% down to only 55%. As any good freshman statistics student could predict, there is a large variation in outcomes between trials with small samples. Extrapolating from Faulkner's findings, usability test designers relying on any single set of five users run the risk that nearly half the problems could be missed.
Increasing the number of participants, however, improves the reliability of the findings quickly. Drawing 10 participants instead of five, the simulation uncovered 95% of the problems on average with a lower bound of 82% of problems identified over 100 simulations. With 15 participants, 97% of the identified problems were uncovered on average, with a lower bound of 90% found.
So? How many then?
So what's the answer? As always in usability, the answer is "It depends." The key to effective usability testing is recruiting a truly representative sample of the target population. Often the test population will need to represent more than one user group.
That aside, Faulkner's work strongly indicates that a single usability test with five participants is not enough.
References
Faulkner, L. (2003). Beyond the five-user assumption: Benefits of increased sample sizes in usability testing. Behavior Research Methods, Instruments and Computers, 35(3), 379-383.
Grosvenor, L. (1999). Software usability: Challenging the myths and assumptions in an emerging field. Unpublished master¹s thesis, University of Texas, Austin.
Landauer, T. K., & Nielsen, J. (1993). A mathematical model of the finding of usability problems. Interchi ¹93, ACM ComputerHuman Interface Special Interest Group.
Nielsen, J. (1993). Usability engineering. Boston: AP Professional.
Perfetti, C., & Landesman, L. (2002). Eight is not enough. Retrieved April 14, 2003.
Spool, J., & Schroeder, W. (2001). Testing web sites: Five users is nowhere near enough. In CHI 2001 Extended Abstracts (pp. 285- 286). New York: ACM Press.
Virzi, R. A. (1992). Refining the test phase of usability evaluation: How many subjects is enough? Human Factors, 34, 457-468.
Woolrych, A., & Cockton, G. (2001). Why and when five test users aren't enough. In J. Vanderdonckt, A. Blandford, & A. Derycke (Eds.), Proceedings of IHM-HCI 2001 Conference: Vol. 2 (pp. 105- 108). Toulouse, France: Cépadèus.
Message from the CEO, Dr. Eric Schaffer — The Pragmatic Ergonomist

So for a routine usability test run 12 people for each segment. For an important one where the stakes are high run 30. If resources are really tight, you can drop to five-six per segment, but this is bad.
Remember I said "FOR EACH SEGMENT." If you are designing a time reporting system for health care workers, government employees, lawyers, and forestry workers, you are making a big mistake if you test just three in each group. That would be 12 people tested, but the groups are quite diverse and you need more people from each segment to be confident.
Leave a comment here
Reader comments
Martha Roden
Usability Engineer
CoCreate Software Inc.
Regarding the "Is 5 Enough?" debate in your newsletter.
If you are the only interaction designer and usability professional in a company of 400 people, AND no one really thinks usability tests are important or wants to free up additional resources to conduct the tests... then believe me ... 5 is definitely better than none!
Five people still find more usability problems than zero people.
James R. (Jim) Lewis, Ph.D., CHFP
Senior Human Factors Engineer
IBM Pervasive Computing Division
As always, I enjoyed the newsletter. I guess I can understand the frustration with the recurring question of sample sizes for usability studies, but it can be an important issue, and the various explorations of it have enhanced our understanding of some of our practices (or at least led to some interesting discussions).
I've ordered the Faulkner paper, and am looking forward to reading it. It sounds similar in method and results to a paper that I published in 2001:
Lewis, J. R. (2001). Evaluation of procedures for adjusting problem-discovery rates estimated from small samples. Journal of Human-Computer Interaction, 13, 445-479.
I was a little surprised that you didn't mention the paper that I published in Human Factors in 1994:
Lewis, J. R. (1994a). Sample sizes for usability studies: Additional considerations. Human Factors, 36, 368-378.
More...Subscribe
Sign up to get our Newsletter delivered straight to your inbox
Privacy policy
Reviewed: 18 Mar 2014
This Privacy Policy governs the manner in which Human Factors International, Inc., an Iowa corporation (“HFI”) collects, uses, maintains and discloses information collected from users (each, a “User”) of its humanfactors.com website and any derivative or affiliated websites on which this Privacy Policy is posted (collectively, the “Website”). HFI reserves the right, at its discretion, to change, modify, add or remove portions of this Privacy Policy at any time by posting such changes to this page. You understand that you have the affirmative obligation to check this Privacy Policy periodically for changes, and you hereby agree to periodically review this Privacy Policy for such changes. The continued use of the Website following the posting of changes to this Privacy Policy constitutes an acceptance of those changes.
Cookies
HFI may use “cookies” or “web beacons” to track how Users use the Website. A cookie is a piece of software that a web server can store on Users’ PCs and use to identify Users should they visit the Website again. Users may adjust their web browser software if they do not wish to accept cookies. To withdraw your consent after accepting a cookie, delete the cookie from your computer.
Privacy
HFI believes that every User should know how it utilizes the information collected from Users. The Website is not directed at children under 13 years of age, and HFI does not knowingly collect personally identifiable information from children under 13 years of age online. Please note that the Website may contain links to other websites. These linked sites may not be operated or controlled by HFI. HFI is not responsible for the privacy practices of these or any other websites, and you access these websites entirely at your own risk. HFI recommends that you review the privacy practices of any other websites that you choose to visit.
HFI is based, and this website is hosted, in the United States of America. If User is from the European Union or other regions of the world with laws governing data collection and use that may differ from U.S. law and User is registering an account on the Website, visiting the Website, purchasing products or services from HFI or the Website, or otherwise using the Website, please note that any personally identifiable information that User provides to HFI will be transferred to the United States. Any such personally identifiable information provided will be processed and stored in the United States by HFI or a service provider acting on its behalf. By providing your personally identifiable information, User hereby specifically and expressly consents to such transfer and processing and the uses and disclosures set forth herein.
In the course of its business, HFI may perform expert reviews, usability testing, and other consulting work where personal privacy is a concern. HFI believes in the importance of protecting personal information, and may use measures to provide this protection, including, but not limited to, using consent forms for participants or “dummy” test data.
The Information HFI Collects
Users browsing the Website without registering an account or affirmatively providing personally identifiable information to HFI do so anonymously. Otherwise, HFI may collect personally identifiable information from Users in a variety of ways. Personally identifiable information may include, without limitation, (i)contact data (such as a User’s name, mailing and e-mail addresses, and phone number); (ii)demographic data (such as a User’s zip code, age and income); (iii) financial information collected to process purchases made from HFI via the Website or otherwise (such as credit card, debit card or other payment information); (iv) other information requested during the account registration process; and (v) other information requested by our service vendors in order to provide their services. If a User communicates with HFI by e-mail or otherwise, posts messages to any forums, completes online forms, surveys or entries or otherwise interacts with or uses the features on the Website, any information provided in such communications may be collected by HFI. HFI may also collect information about how Users use the Website, for example, by tracking the number of unique views received by the pages of the Website, or the domains and IP addresses from which Users originate. While not all of the information that HFI collects from Users is personally identifiable, it may be associated with personally identifiable information that Users provide HFI through the Website or otherwise. HFI may provide ways that the User can opt out of receiving certain information from HFI. If the User opts out of certain services, User information may still be collected for those services to which the User elects to subscribe. For those elected services, this Privacy Policy will apply.
How HFI Uses Information
HFI may use personally identifiable information collected through the Website for the specific purposes for which the information was collected, to process purchases and sales of products or services offered via the Website if any, to contact Users regarding products and services offered by HFI, its parent, subsidiary and other related companies in order to otherwise to enhance Users’ experience with HFI. HFI may also use information collected through the Website for research regarding the effectiveness of the Website and the business planning, marketing, advertising and sales efforts of HFI. HFI does not sell any User information under any circumstances.
Disclosure of Information
HFI may disclose personally identifiable information collected from Users to its parent, subsidiary and other related companies to use the information for the purposes outlined above, as necessary to provide the services offered by HFI and to provide the Website itself, and for the specific purposes for which the information was collected. HFI may disclose personally identifiable information at the request of law enforcement or governmental agencies or in response to subpoenas, court orders or other legal process, to establish, protect or exercise HFI’s legal or other rights or to defend against a legal claim or as otherwise required or allowed by law. HFI may disclose personally identifiable information in order to protect the rights, property or safety of a User or any other person. HFI may disclose personally identifiable information to investigate or prevent a violation by User of any contractual or other relationship with HFI or the perpetration of any illegal or harmful activity. HFI may also disclose aggregate, anonymous data based on information collected from Users to investors and potential partners. Finally, HFI may disclose or transfer personally identifiable information collected from Users in connection with or in contemplation of a sale of its assets or business or a merger, consolidation or other reorganization of its business.
Personal Information as Provided by User
If a User includes such User’s personally identifiable information as part of the User posting to the Website, such information may be made available to any parties using the Website. HFI does not edit or otherwise remove such information from User information before it is posted on the Website. If a User does not wish to have such User’s personally identifiable information made available in this manner, such User must remove any such information before posting. HFI is not liable for any damages caused or incurred due to personally identifiable information made available in the foregoing manners. For example, a User posts on an HFI-administered forum would be considered Personal Information as provided by User and subject to the terms of this section.
Security of Information
Information about Users that is maintained on HFI’s systems or those of its service providers is protected using industry standard security measures. However, no security measures are perfect or impenetrable, and HFI cannot guarantee that the information submitted to, maintained on or transmitted from its systems will be completely secure. HFI is not responsible for the circumvention of any privacy settings or security measures relating to the Website by any Users or third parties.
Correcting, Updating, Accessing or Removing Personal Information
If a User’s personally identifiable information changes, or if a User no longer desires to receive non-account specific information from HFI, HFI will endeavor to provide a way to correct, update and/or remove that User’s previously-provided personal data. This can be done by emailing a request to HFI at hfi@humanfactors.com. Additionally, you may request access to the personally identifiable information as collected by HFI by sending a request to HFI as set forth above. Please note that in certain circumstances, HFI may not be able to completely remove a User’s information from its systems. For example, HFI may retain a User’s personal information for legitimate business purposes, if it may be necessary to prevent fraud or future abuse, for account recovery purposes, if required by law or as retained in HFI’s data backup systems or cached or archived pages. All retained personally identifiable information will continue to be subject to the terms of the Privacy Policy to which the User has previously agreed.
Contacting HFI
If you have any questions or comments about this Privacy Policy, you may contact HFI via any of the following methods:
Human Factors International, Inc.
PO Box 2020
1680 highway 1, STE 3600
Fairfield IA 52556
hfi@humanfactors.com
(800) 242-4480
Terms and Conditions for Public Training Courses
Reviewed: 18 Mar 2014
Cancellation of Course by HFI
HFI reserves the right to cancel any course up to 14 (fourteen) days prior to the first day of the course. Registrants will be promptly notified and will receive a full refund or be transferred to the equivalent class of their choice within a 12-month period. HFI is not responsible for travel expenses or any costs that may be incurred as a result of cancellations.
Cancellation of Course by Participants (All regions except India)
$100 processing fee if cancelling within two weeks of course start date.
Cancellation / Transfer by Participants (India)
4 Pack + Exam registration: Rs. 10,000 per participant processing fee (to be paid by the participant) if cancelling or transferring the course (4 Pack-CUA/CXA) registration before three weeks from the course start date. No refund or carry forward of the course fees if cancelling or transferring the course registration within three weeks before the course start date.
Cancellation / Transfer by Participants (Online Courses)
$100 processing fee if cancelling within two weeks of course start date. No cancellations or refunds less than two weeks prior to the first course start date.
Individual Modules: Rs. 3,000 per participant ‘per module’ processing fee (to be paid by the participant) if cancelling or transferring the course (any Individual HFI course) registration before three weeks from the course start date. No refund or carry forward of the course fees if cancelling or transferring the course registration within three weeks before the course start date.
Exam: Rs. 3,000 per participant processing fee (to be paid by the participant) if cancelling or transferring the pre agreed CUA/CXA exam date before three weeks from the examination date. No refund or carry forward of the exam fees if requesting/cancelling or transferring the CUA/CXA exam within three weeks before the examination date.
No Recording Permitted
There will be no audio or video recording allowed in class. Students who have any disability that might affect their performance in this class are encouraged to speak with the instructor at the beginning of the class.
Course Materials Copyright
The course and training materials and all other handouts provided by HFI during the course are published, copyrighted works proprietary and owned exclusively by HFI. The course participant does not acquire title nor ownership rights in any of these materials. Further the course participant agrees not to reproduce, modify, and/or convert to electronic format (i.e., softcopy) any of the materials received from or provided by HFI. The materials provided in the class are for the sole use of the class participant. HFI does not provide the materials in electronic format to the participants in public or onsite courses.